今天就來繼續從範例中學習吧!
首先是將語音翻譯並以文字顯示的translate-speech-to-text
介面如下,按下Start recognition後開始辨識語音
偵測到一段時間的沉默時
便會停止辨識並將翻譯結果的文字顯示在Results的文字框中
今天還錄了個影片
讓Google小姐唸了一段新聞來辨識
結果似乎把won辨識成want了XD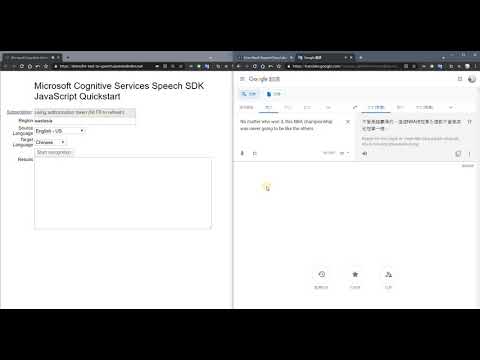
至於部署方式就跟前兩天一樣
就不多贅述了
直接來看程式碼吧!
前後相同的部分也不再重複了
直接跳到141-143行的辨識語言及目標語言
speechConfig.speechRecognitionLanguage = languageSourceOptions.value;
let language = languageTargetOptions.value
speechConfig.addTargetLanguage(language)
將建立好的speechConfig的語音辨識語言speechRecognitionLanguage指定為網頁頁面中Source Language選擇的值
並將網頁頁面中Target Language的值透過addTargetLanguaget傳入
其他就如同之前一樣
初始化辨識器、辨識完成顯示在網頁的文字框中等
便可以完成語音辨識並翻譯為指定語言即顯示為文字
—
另外還有翻譯成多語言甚至聊天室的範例
感覺有點超出語音辨識的範疇了
就不在這個系列研究分享
有興趣的話一樣把GitHub上的檔案在有SSL認證的網頁伺服器執行即可
那語音辨識的簡單研究就差不多到這邊!

